Let there be flow – Die Magie hinter Kanban und Flow
06. Oktober 2021
Ein Konzept findet in der Softwareentwicklung in letzter Zeit immer mehr Beachtung: Kanban. Von den einen als die bessere agile Alternative gepriesen, von anderen wegen der Flexibilität und Einfachheit geliebt. Dabei ist Kanban gar nicht so neu, wie es oftmals scheint. Dieser Artikel möchte die zugrunde liegenden Prinzipien erläutern und so ein besseres Verständnis schaffen.
Kanban wurde bereits 1947 von Taiichi Ohno bei Toyota entwickelt, stammt also aus der Fertigung. Lediglich die Anwendung von Kanban in der Softwareentwicklung ist relativ neu. David J. Anderson hat dazu 2003 ein Buch veröffentlicht, das als Ausgangspunkt für diese Bewegung gilt. Kanban wird oft auf wenige Kernpraktiken reduziert, ohne dass dabei die Wirkmechanismen im Hintergrund ausreichend verstanden werden. Schauen wir uns diese deshalb genauer an.
Kanban = Optimierung von Flow
Ein wesentliches Ziel von Kanban ist es, den sogenannten Flow, also den Fluss der Arbeit durch ein System zu optimieren. Das System stell dabei typischerweise die Bearbeitung einer Funktionalität von der Anforderung bis zur Auslieferung dar - hierzu später mehr.
Warum ist die Optimierung von Flow aber so entscheidend? Viele Systeme werden heute vor allem auf maximale Auslastung hin optimiert oder, um das etwas positiver zu formulieren, es sollen Leerlaufzeiten bei den Bearbeitenden minimiert werden. Dass diese Optimierung auf Auslastung oftmals keine so gute Idee ist, lässt sich an einem kleinen Beispiel sehr gut verdeutlichen.
Wir stellen uns eine Autobahn vor. Während in der einen Fahrtrichtung nicht sehr viel Verkehr ist, bewegen sich die Fahrzeuge in der Gegenrichtung nur im Schritttempo. Während in der einen Richtung immer wieder auch größere Abstände zwischen den Fahrzeugen sind, stehen in der anderen Richtung PKWs und LKWs Stoßstange an Stoßstange.
Die Frage ist nun, wo ist die Autobahn besser ausgelastet? Sicherlich auf der Seite mit dem Stau. Dort haben wir deutlich mehr Fahrzeuge pro Fläche Autobahn als auf der Seite, auf der der Verkehr flüssig läuft. Aber wo ist der Durchsatz höher, also wo werden mehr Fahrzeuge je Zeiteinheit einen bestimmten Punkt passieren? Vermutlich bei flüssigem Verkehr. Genau das ist das äquivalent von Flow. Genau diesen Zustand wollen wir auch in unserem System, das Software erstellt, erreichen. Dort sollen die Features und Bug-Fixes auch möglichst zügig und reibungslos durchfließen, statt sich zu stauen und ewig darauf zu warten, endlich fertig zu werden.
Welche Vorteile ein optimierter Flow bietet und wie das erreicht werden kann, das soll in diesem Artikel beleuchtet werden. Einige der hier vorgestellten Konzepte sind kontraintuitiv und erscheinen zunächst unlogisch. Deshalb verlangt der Artikel von den Lesern ein hohes Maß an Offenheit ab, um die hier vorgestellten Konzepte nicht vorschnell abzulehnen. Es lohnt sich definitiv, tiefer in die Welt des Flows einzutauchen.
Kanban Kernpraktiken
Kanban basiert auf vier wesentlichen Kernpraktiken:
- Visualisiere den Fluss der Arbeit.
- Begrenze die Menge angefangener Arbeit.
- Miss und steuere den Fluss.
- Mache die Regeln für den Prozess explizit und passe sie nach Bedarf an.
Diese Praktiken lassen sich auf nahezu jeden bestehenden Prozess anwenden. Damit ist Kanban weniger als Prozess zu verstehen, sondern vielmehr als eine Prozessverbesserungsmethodik, die genutzt werden kann, beliebige Prozesse zu verbessern. Zudem ist Kanban nicht zwingend auf die agile Softwareentwicklung beschränkt, auch wenn es sich dort besonders gut anwenden lässt. Auch klassische Vorgehen wie beispielsweise mit dem V-Modell könnten mit Hilfe von Kanban optimiert werden. Im Folgenden wollen wir diese Kernpraktiken und deren konkrete Umsetzung näher betrachten.
Schritt 1 - Fluss der Arbeit visualisieren
Als ersten Schritt muss ein gemeinsames Verständnis davon geschaffen werden, wie die Arbeit durch unser System bewegt wird. Diese Definition bezeichnen wir im Weiteren als Workflow. Teilweise sieht man statt Arbeit auch den Begriff Nutzen oder Wert bzw. den englischen Begriff Value und daraus folgend auch den Begriff Value Stream als äquivalent zum Workflow.
Zunächst müssen der Start- und der Endpunkt für unseren Workflow festgelegt werden. Das mag zunächst trivial klingen, wirft bei näherer Betrachtung aber auch viele Fragen auf. Startet unser Workflow dann, wenn ein neuer Featurewunsch von einem Kunden oder einer anderen Person gemeldet wird oder erst dann, wenn wir wirklich beginnen, daran zu arbeiten? Endet der Workflow, wenn das Feature umgesetzt wurde, wenn es getestet ist oder wenn es ausgeliefert und durch die Kunden genutzt werden kann? Unterscheiden sich diese Definitionen für neue Features und die Behebung von Fehlern? Diese unterschiedlichen Definitionen der Grenzen unseres Workflows haben wichtige Auswirkungen, auf die wir etwas später noch näher eingehen wollen. Für den Moment genügt es festzuhalten, dass es verschiedene valide Optionen gibt und es zunächst nur wichtig ist, sich auf eine klare und gemeinsame Definition zu einigen.
Zwischen dem Start und dem Ende des Workflows werden nun verschiedene Aktivitäten beschrieben, die ausgeführt werden müssen, während ein Element unseren Workflow durchläuft. Das können für Softwarefeatures im einfachsten Fall die Stufen „Implementieren“ und „Testen“ sein. Es können aber auch weitere Unterteilungen oder eine andere Definition sinnvoll sein. Damit kann der Workflow wie in Abbildung 1 dargestellt visualisiert werden.
 Abbildung 1 - Start- und Endpunkt sowie Aktivitäten eines simplen Workflows
Abbildung 1 - Start- und Endpunkt sowie Aktivitäten eines simplen Workflows
Ein weiteres wichtiges Konzept in Kanban ist das sogenannte Pull-Prinzip. Das bedeutet, dass ein Element aktiv in eine Aktivität „gezogen“ wird, wenn dafür Kapazität vorhanden ist, statt dass die vorausgehende Station fertige Arbeit in diese Aktivität schiebt. Die Wichtigkeit des Pull-Prinzips wird deutlich, wenn wir später noch über das Konzept von Engpässen bzw. Bottlenecks sprechen. Für den Moment soll lediglich erläutert werden, wie wir das Pull-Prinzip in unserem Workflow ermöglichen. Dazu unterteilen wir die Aktivitätsspalten in einen Bereich für Elemente, an denen aktiv gearbeitet wird und Elemente, die in dieser Aktivität abgeschlossen sind und somit bereit sind, in die nächste Aktivität gezogen zu werden (Abb.2).
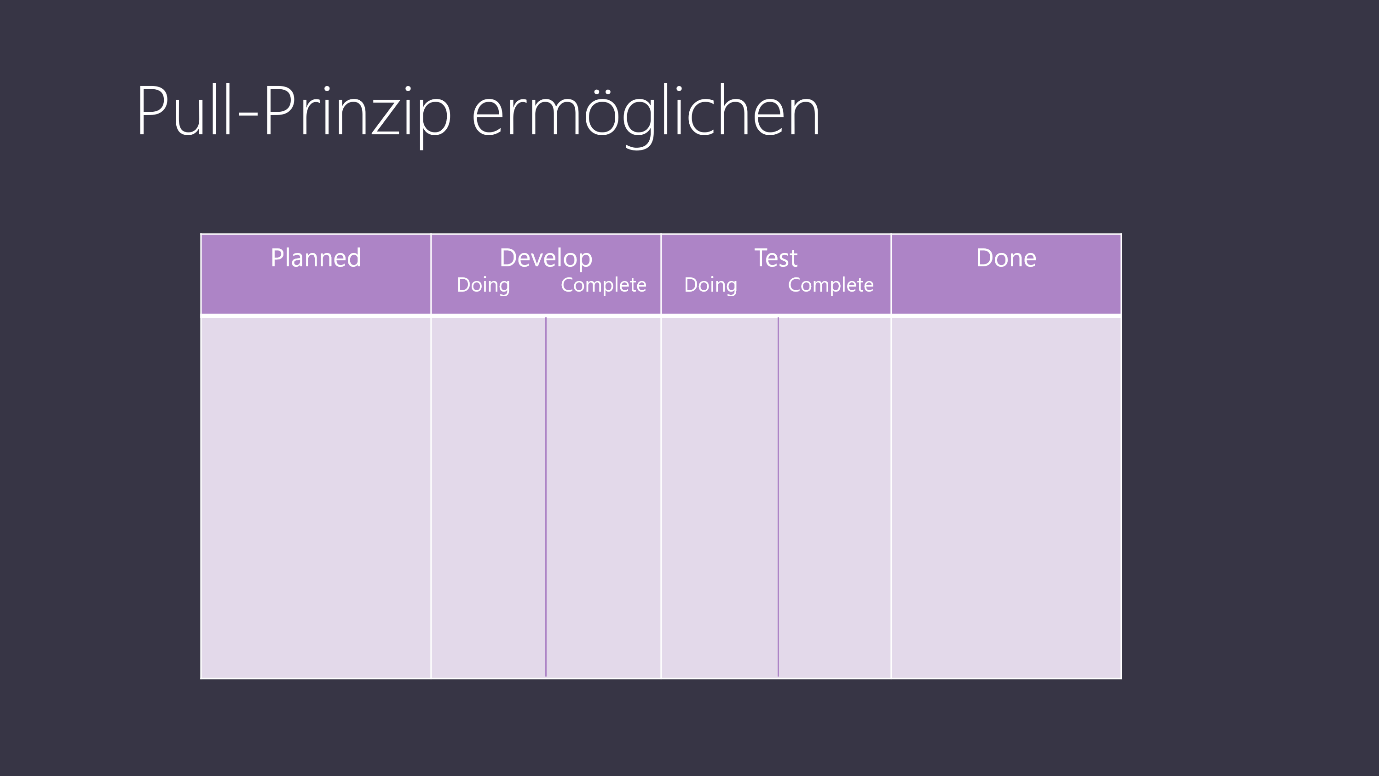 Abbildung 2 - Spalten unterteilen, um das Pull-Prinzip zu ermöglichen
Abbildung 2 - Spalten unterteilen, um das Pull-Prinzip zu ermöglichen
Für eine Softwareentwicklung kann das z.B. bedeuten, dass ein Mitglied des Entwicklerteams sich entscheidet, an einem neuen Feature zu arbeiten. Dieses Element wird dann aus der Spalte „Planned“ in „Develop / Doing“ gezogen. Wenn die Implementierung abgeschlossen ist, wandert das Element in „Develop / Complete“. Nun kann ein anderes Teammitglied dieses Element testen und visualisiert das dadurch, dass das Element in „Test / Doing“ gezogen wird. Nach Abschluss des Tests steht das Element in „Test / Complete“ und kann nun z.B. nach einem erfolgreichen Deployment in „Done“ verschoben werden.
In einem weiten Schritt legt die Definition unseres Workflows fest, welche Arten von Arbeitselementen wir unterscheiden möchten und wie wir diese visualisieren. Die Visualisierung kann dabei beispielsweise über Farben erfolgen.
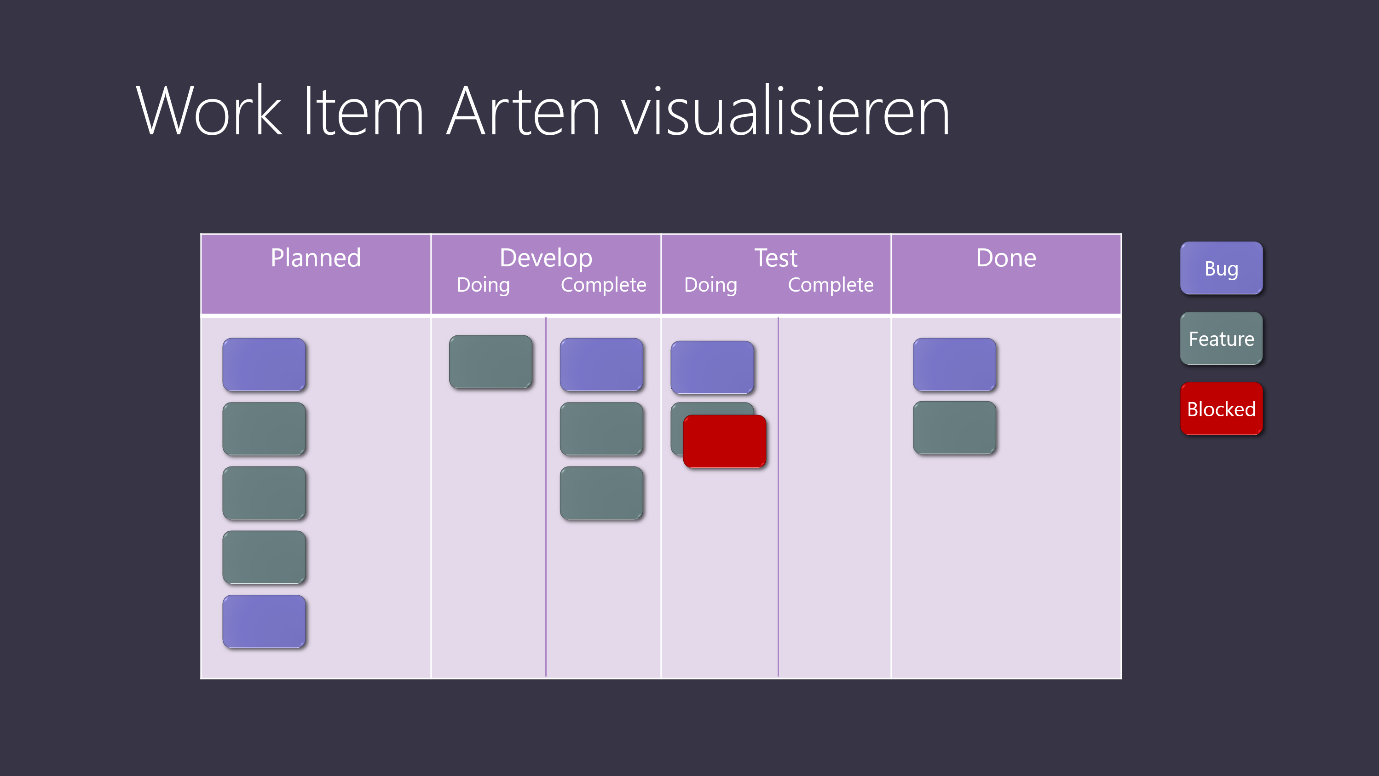 Abbildung 3 - Visualisierung der Work Item Arten und Blocker
Abbildung 3 - Visualisierung der Work Item Arten und Blocker
Eine Besonderheit in Abbildung 3 ist die Visualisierung von sog. Blockern. Ein Blocker visualisiert, wenn ein Element momentan nicht bearbeitet werden kann. Dies kann z.B. dann der Fall sein, wenn auf wichtige Informationen oder Materialien gewartet wird, wenn Abhängigkeiten zu teamexternen Personen eine Weiterbearbeitung verzögern oder aber auch wenn unerwartete Probleme die Fertigstellung verzögern. Es ist wichtig, dass diese Blocker nicht in eine separate Spalte verschoben werden, sondern in dem aktuellen Prozessschritt verbleiben und entsprechend gekennzeichnet werden.
Schritt 2 - Die Menge der angefangenen Arbeit begrenzen
Auf den ersten Blick scheint es nicht unbedingt zielführend, die Menge an angefangener Arbeit (Work in Process = WIP) zu begrenzen. Es scheint natürlicher, neue Aufgaben zu beginnen, wenn an einer Aufgabe, aus welchen Gründen auch immer, nicht weitergearbeitet werden kann oder wenn eine Teilaktivität abgeschlossen und die Aufgabe an jemand anderen übergeben wurde. Das liegt daran, dass häufig das Ziel darin besteht, dass alle Mitglieder eines Teams möglichst zu jeder Zeit etwas zu tun haben sollten. Zeiten, in denen jemand nicht aktiv an einer Aufgabe arbeitet, scheinen Verschwendung zu sein. Das ist eines der Beispiele, wie Flow-Prinzipien kontraintuitiv sein können und es deshalb eines tieferen Verständnisses bedarf, diese tatsächlich umzusetzen. Deshalb wollen wir uns kurz ein wenig mit der Theorie hinter der Limitierung von WIP beschäftigen.
Eines der primären Ziele von Flow-Optimierung ist es, die Durchlaufzeiten zu minimieren. Es gibt verschiedene Motivationen für dieses Ziel. Diese alle aufzuzeigen, würde den Rahmen an dieser Stelle sprengen. Deshalb sei hier auf weiterführende Literatur verwiesen (ActionableAgile Metrics for Predictability und When Will It Be Done?). Zusammengefasst hilft eine verkürzte Durchlaufzeit nicht nur die Vorhersagbarkeit für die Fertigstellung von Aufgaben zu erhöhen, sondern verspricht auch deutliche Effizienz- und Qualitätsgewinne.
In vielen Prozessen ist der wesentliche Anteil der Durchlaufzeit durch Wartezeiten geprägt, d.h. Zeiten an denen an einer Aufgabe gar nicht aktiv gearbeitet wird. Diese Wartezeiten haben gegenüber den Bearbeitungszeiten sehr häufig einen wesentlich höheren Anteil wie Abbildung 4 visualisiert.
WIP - Work in Process oder Work in Progress?
Die Abkürzung WIP wird in der Literatur unterschiedlich genutzt. Während man häufig „Work in Progress“ sieht, gibt es auch einige Stellen, die als ausgeschriebene Variante „Work in Process“ verwenden. Der Unterschied mag marginal erscheinen und während die Begrifflichkeit nicht so entscheidend ist, so ist dennoch das gedankliche Modell dahinter wesentlich. Bei „Work in Progress“ stellt sich schnell die Frage, was dazu wirklich zählt. Werden z.B. geblockte Aufgaben mitgezählt? Schließlich sind diese gerade per Definition nicht in Bearbeitung. Zählen Elemente, die in einem bestimmten Prozessschritt abgeschlossen sind und nun auf die Weiterbearbeitung warten „in Progress“? Da es bei der Begrenzung von WIP darum geht, den Fluss zu optimieren, ist es wichtig, dass alle Elemente im System in diese Betrachtung mit einfließen. Der Begriff „Work in Process“ drückt diese Sichtweise besser aus, weshalb diese Formulierung in diesem Artikel verwendet wird.
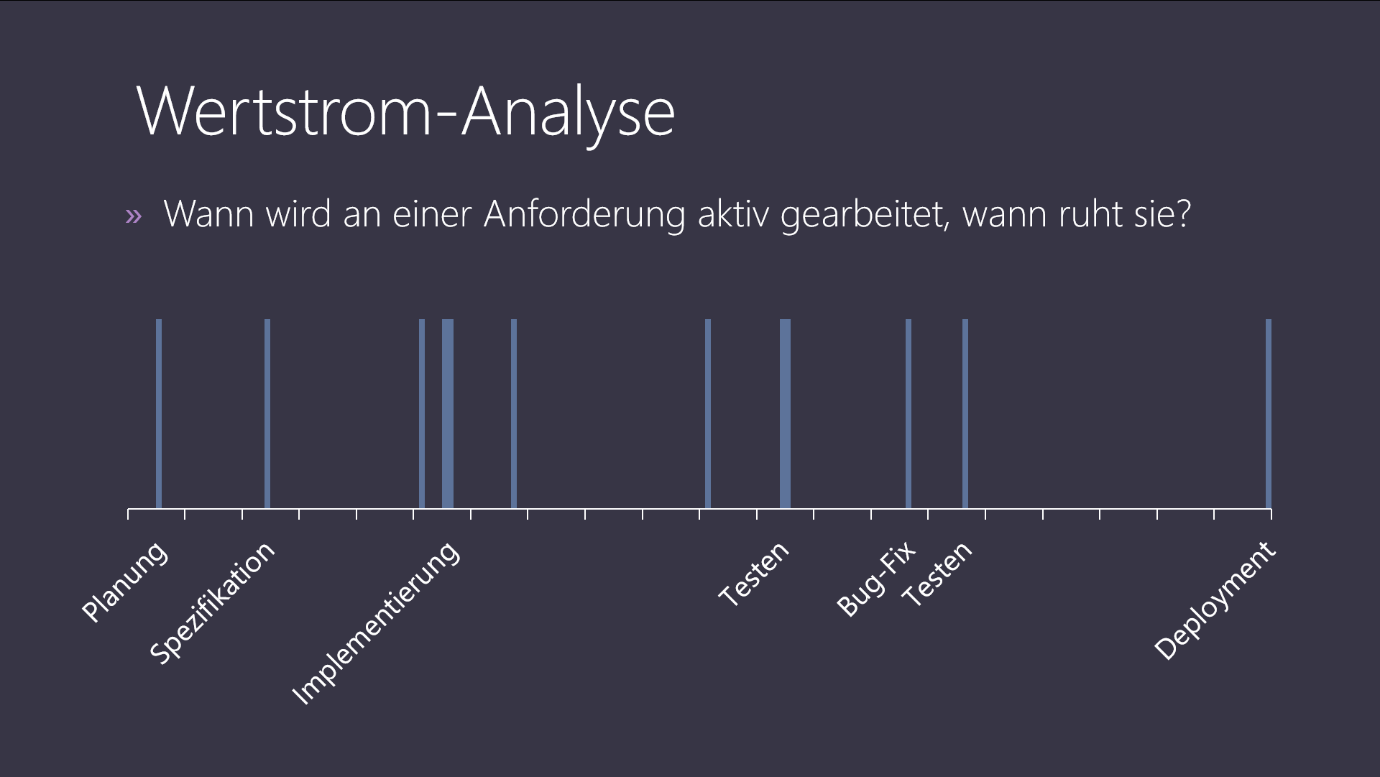 Abbildung 4 - Wertstrom-Analyse - Wartezeiten vs. Bearbeitungszeiten
Abbildung 4 - Wertstrom-Analyse - Wartezeiten vs. Bearbeitungszeiten
Somit ist auch klar, wo angesetzt werden sollte, um die Durchlaufzeiten zu reduzieren. Eine Optimierung der Bearbeitungsgeschwindigkeit wird in dem abgebildeten Beispiel keinen wesentlichen Einfluss auf die Durchlaufzeit haben. Zudem ist es in den meisten Fällen einfacher, die Wartezeiten zu minimieren als Arbeit zu beschleunigen.
Genau hier setzt nun die Begrenzung des „Work in Process“ an. Wir legen für bestimmte Bereiche unseres Workflows eine Maximalanzahl von Elementen fest, die sich in diesem Bereich befinden dürfen. Wird dieses Limit erreicht, so darf keine neue Arbeit in diesem Bereich gestartet werden. Vielmehr sollte der Fokus darauf gelegt werden, die Elemente, die bereits begonnen wurden, abzuschließen und für den nächsten Bearbeitungsschritt bereitzustellen. Der Zusammenhang zwischen WIP und der Durchlaufzeit wurde auch durch John Little in Littles Law beschrieben und mathematisch bewiesen.
 Abbildung 5 - WIP Limits festlegen
Abbildung 5 - WIP Limits festlegen
Wichtig ist dabei, dass sowohl die „Doing“ als auch die „Complete“ Spalte in das WIP eingerechnet werden. In Zusammenhang mit dem Pull-System wird somit eine Balance im gesamten System erreicht. Im in Abbildung 5 dargestellten Beispiel würde es vermutlich wenig Sinn ergeben, wenn weitere Aufgaben in den Bereich „Develop“ gezogen und dort bearbeitet würden. Offensichtlich scheint es im Bereich „Test“ einen Engpass zu geben, der zunächst beseitigt werden sollte. Das verdeutlicht ein weiteres wesentliches Prinzip bei der Optimierung von Flow: System Thinking. Statt nur eine lokale Stelle im Workflow zu optimieren, muss das gesamte System betrachtet werden. Soll der Flow optimiert werden, dann wird die Optimierung dort am wirksamsten sein, wo es einen Engpass gibt. Alle anderen Optimierungen werden weitgehend wirkungslos sein.
Dies lässt sich auch gut mit der Metapher zu Beginn des Artikels verdeutlichen: Wenn der Stau auf der Autobahn z.B. durch einen Unfall verursacht wurde, durch den ein Engpass entsteht, dann macht es Sinn, diese Engstelle so rasch wie möglich zu beseitigen. Eine Optimierung vor oder nach der Engstelle, z.B. durch das Erlauben des Befahrens des Standstreifens würde dagegen den Durchfluss des Verkehrs nicht verbessern.
Das Pull-Prinzip zusammen mit den WIP-Limits sorgt dafür, dass die nachfolgenden Stellen signalisieren, wann es sinnvoll ist, an den vorausgehenden Prozessschritten zu arbeiten. Daher rührt übrigens auch der Name Kanban, was aus dem Japanischen kommt und so viel wie „Signalkarte“ bedeutet. Diese Signalkarte war an einem Transportbehälter befestigt und wenn dieser Behälter an einer Station komplett bearbeitet war, dann wurde die Signalkarte an die vorausgehende Station übergeben, was dort das Signal war, für Nachschub zu sorgen. Das WIP Limit war definiert durch den Platz an jeder Station, der reserviert war, um eine gewisse Menge dieser Transportbehälter aufzunehmen. Dieses Prinzip mündete 1987 in die von Eliyahu M. Goldratt entwickelte „Theory of Constraints“
Schritt 3 - Regeln für den Prozess explizit machen
Innerhalb des Workflows gilt es nun, gewisse Regeln explizit zu machen und so ein gemeinsames Verständnis zu schaffen. Das ist die Voraussetzung für eine Anpassung dieser Regeln mit dem Ziel, den Flow zu optimieren. Im Folgenden sollen einige der wichtigsten Regeln im Workflow beschrieben werden
Exit Criteria
Mit Hilfe von Exit Criteria wird ein gemeinsames Verständnis davon geschaffen, was erfüllt sein muss, um einen bestimmten Prozessschritt im Workflow als abgeschlossen zu betrachten. Diese Exit Criteria werden demnach pro Spalte festgelegt. In den Spalten, die in „Doing“ und „Complete“ unterteilt werden, bestimmen sie also, wann ein Element in die „Complete“ Spalte übergehen kann. Als Beispiel für „Develop“ könnten das z.B. Punkte sein wie:
- Code Review wurde durcheführt.
- Der Build ist grün.
- Die technische Dokumentation wurde angepasst.
Diese Exit Criteria sollen bei einem weiteren Aspekt unterstützen, der für die Optimierung von Flow wichtig ist: Arbeit soll in unserem Workflow möglichst nur in eine Richtung fließen. Das bedeutet, dass Nacharbeiten verhindert werden sollen. Dafür ist es wichtig, dass in jedem Prozessschritt auf Qualität geachtet wird. Sie soll nicht erst am Ende hineingetestet werden. Die Exit Criteria definieren also Qualitätsattribute für jeden Schritt. Jeder Qualitätsmangel, der in einem späteren Schritt festgestellt wird, sollte genutzt werden, um die Qualität im gesamten System zu verbessern. Diese Verbesserungen drücken sich dann oftmals in angepassten Exit Criteria aus.
Pull Policies
Erlaubt das WIP Limit eine neue Aufgabe zu beginnen, ist eine wichtige Frage, woran als nächstes gearbeitet werden soll. Das regelt die sog. Pull Policy. Dort ist festgelegt, nach welchen Kriterien vorgegangen werden soll. Beispielsweise könnte ein Team folgende Pull Policy festlegen:
- Blocker haben Vorrang
- ältere Items haben Vorrang
- Pull, wenn WIP Limit unterschritten wird
Die Pull Policy hat einen entscheidenden Einfluss auf die Varianz der Durchlaufzeit. Je geringer diese Varianz, desto besser die Prognosegüte des Systems. Erstaunlicherweise werden für die Prognosegüte Faktoren wie WIP Limits und die Pull Policy unterschätzt, während der Einfluss der Größe einer Aufgabe überschätzt wird. Dieses nicht unumstrittene Konzept führte zu der #NoEstimate-Bewegung, die zum Teil heftige Debatten in Sozialen Medien und darüber hinaus ausgelöst hat. An dieser Stelle soll der Leser eher dazu motiviert werden, die Flow-Prinzipien zusätzlich in Betracht zu ziehen, statt eine Grundsatzdebatte über die Sinnhaftigkeit von Aufwandsschätzungen anzustoßen.
Service Level Expectations (SLE)
Die Service Level Expectation drückt die zu erwartende Durchlaufzeit mit einer gewissen Wahrscheinlichkeit aus, also z.B.:
- 7 Tage oder weniger mit 50 Prozent Wahrscheinlichkeit
- 16 Tage oder weniger mit 85 Prozent Wahrscheinlichkeit
Diese Formulierung verdeutlich sehr klar, dass die Aussagen für eine Fertigstellung immer mit einer gewissen Wahrscheinlichkeit verbunden sind. Je höher die Verlässlichkeit der Aussage sein soll, desto länger wird auch der Zeitraum sein. Die Definition einer SLE erlaubt nun einen entsprechenden Dialog mit den Anforderern. Diese können entscheiden, welche Verlässlichkeit der Prognose sie benötigen.
Die SLE wird üblicherweise aus historischen Daten abgeleitet. Sobald die ersten Werte für die Durchlaufzeit ermittelt wurden, können sie in einem sog. Cycle Time Scatter Plot (Abb.6) dargestellt werden. Dabei wird auf der X-Achse das Datum der Fertigstellung eingetragen, auf der Y-Achse die Cycle Time, also die Durchlaufzeit für jedes Element. Nun können in diesem Diagramm die sogenannten Perzentilen eingetragen werden. Die 50-%-Perzentile wird dort platziert, wo 50 Prozent der Elemente unterhalb oder auf dieser Linie liegen, die 85-% Perzentile entsprechend bei 85 Prozent der Elemente, die unterhalb oder auf dieser Linie liegen. Nun kann auf der Y-Achse für jede Perzentile die Durchlaufzeit für die SLE abgelesen werden.
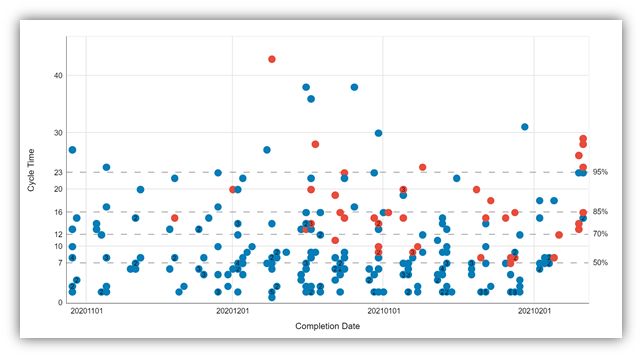 Abbildung 6 - Cycle Time Scatter Plot
Abbildung 6 - Cycle Time Scatter Plot
Für eine Optimierung des Prozesses und der Abläufe gibt die SLE nun auch einen sehr guten Hinweis, welche Elemente näher betrachtet werden sollen. Schließlich macht es weniger Sinn, die 85 Prozent der Elemente zu betrachten, die innerhalb der vorgesehenen SLE abgeschlossen werden konnten. Aufschlussreicher ist vermutlich, die 15 Prozent der Elementen näher zu analysieren, deren Umsetzung länger gedauert hat, als die SLE vorgibt.
Schritt 4 - Den Fluss der Arbeit aktiv überwachen und steuern
Nachdem der Workflow nun in einer ersten Version inkl. den Regeln und den WIP Limits festgelegt wurde, geht es nun darum, diese Werkzeuge aktiv zur Verbesserung des Flows zu nutzen. Dabei sollen Störungen im Ablauf identifiziert und dafür Verbesserungen implementiert werden. Was sich trivial und selbstverständlich anhört, hat jedoch weitreichende Auswirkungen auf die Arbeitsweise eines Softwareentwicklungsteams. Die Perspektive muss hier gewechselt werden, von der möglichst optimalen Auslastung der Personen hin zu einem möglichst reibungslosen Fluss der Elemente.
Das bedeutet, dass nicht jeder im Team, der eine Aufgabe abgeschlossen hat, sofort die nächste Aufgabe beginnt. Denn in diesem Fall würde vermutlich eine Wartezeit entstehen, wenn kurz darauf eine andere Aufgabe in einem Teilschritt abgeschlossen wurde und weiterbearbeitet werden kann. Das ist beispielsweise dann der Fall, wenn eine Implementierung abgeschlossen wurde und auf einen Code Review wartet, weil momentan alle Teammitglieder mit anderen Aufgaben beschäftigt sind.
Aus der Perspektive des Flows wäre ein Single-Piece-Flow ideal, also die Bearbeitung einer einzelnen Aufgabe zu jedem Zeitpunkt. Ist ein Teilschritt für eine Aufgabe abgeschlossen, würde die nächste Person bereits bereitstehen und sofort mit der Weiterbearbeitung beginnen. Somit wären die Wartezeiten minimal und die Durchlaufzeit würde reduziert. Jedoch ist das in der Praxis oft nur schwer umzusetzen. Ein Konzept, das diesem Vorgehen sehr nahekommt, ist Mob-Programming. In der Praxis wird wohl häufig versucht werden, einen Mittelweg zwischen diesen beiden Extremen zu erreichen, was bereits eine Verbesserung gegenüber der auslastungsorientierten Realität der meisten Teams darstellt.
Eine weitere Technik, mit der Flow überwacht und gesteuert werden kann, ist das sog. Work Item Aging. Dabei wird für jedes Element festgestellt, wie lange es sich bereits im Prozess befindet. Dieses „Alter“ eines Elements kann dann mit der SLE abgeglichen und so festgestellt werden, wo es voraussichtlich zu einer Überschreitung kommen wird. Dieser Überschreitung sollte aktiv entgegengewirkt werden, indem der Fokus des Teams auf dieses Element gelegt wird. Dadurch werden Ausreißer der Durchlaufzeit vermieden, das System wird wesentlich weniger Schwankungen unterliegen und der Fluss wird somit verbessert.
Eine wichtige Rolle für die Optimierung des Flows spielt nun, wie wir den Start- und den Endpunkt unseres Workflows definiert haben. Nur für diesen Bereich greifen unsere Visualisierung und die erwähnten Metriken. Somit macht es sehr wohl einen Unterschied, ob der Workflow damit endet, dass die Implementierung inkl. Qualitätssicherung abgeschlossen und das Feature genutzt werden könnte oder ob das Deployment bis zum Anwender inkludiert ist. Ist das Product Backlog Teil unseres Workflows? Das wird vermutlich bei vielen Teams dazu führen, dass die Durchlaufzeiten stark durch die Wartezeit im Product Backlog bestimmt werden. Vielleicht lohnt es sich, zu überlegen, wie ein solches System dann verändert werden müsste.
Vermutlich würde ein WIP-Limit für das Product Backlog festgelegt werden, um die Anzahl der Elemente, die wir Anwendern versprochen haben, zu limitieren. Mit Hilfe der SLE könnte Anwendern eine Prognose kommuniziert werden, wann Elemente aus dem Product Backlog vermutlich fertiggestellt werden. Und die Pflege des Product Backlogs würde wesentlich weniger Zeit in Anspruch nehmen. Statt alle möglichen Wünsche aufzunehmen, die vermutlich erst sehr viel später, wenn überhaupt, umgesetzt werden, fokussieren wir uns auf die Dinge, die im Moment gerade wichtig sind. Der Flow vom Kundenwunsch bis hin zur Nutzung durch die Anwender wird dadurch betrachtet und optimiert. Abbildung 7 zeigt einen solchen erweiterten Workflow.
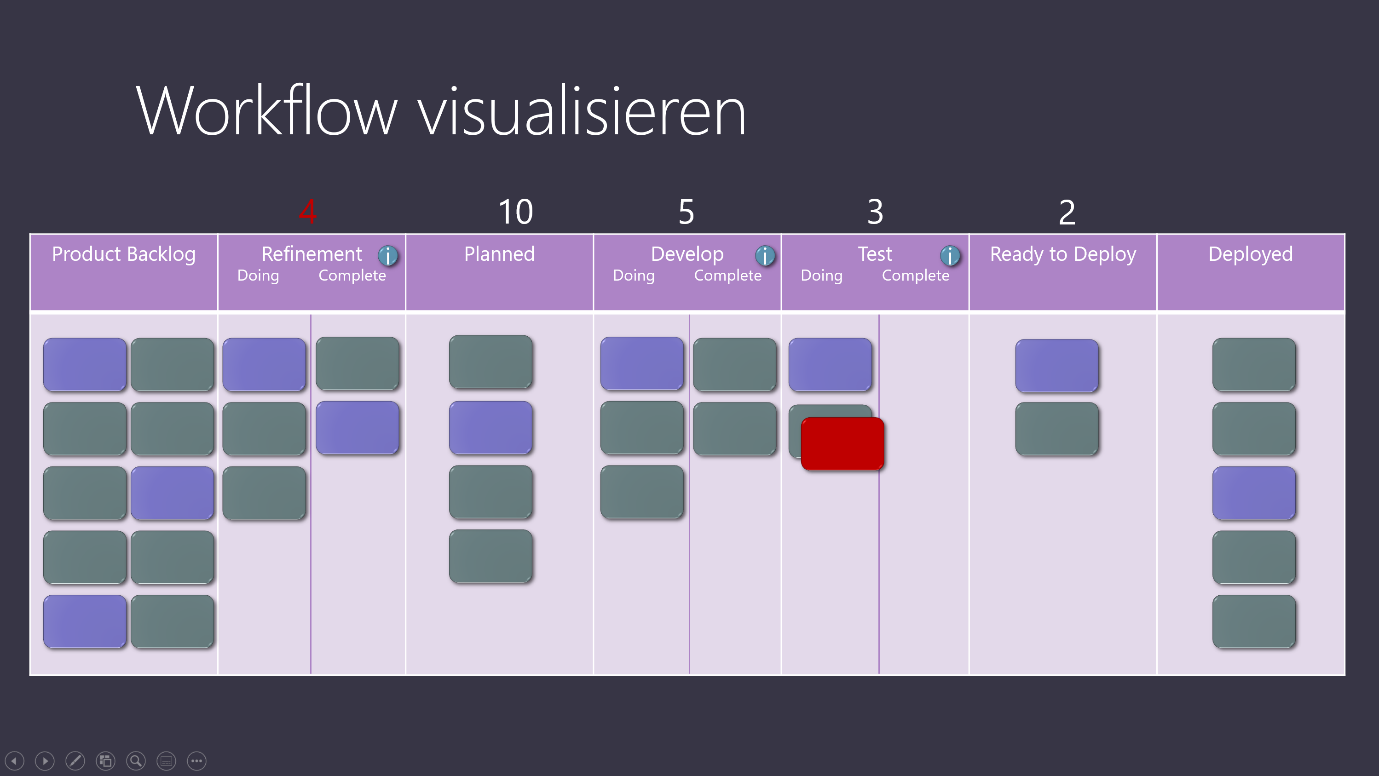 Abbildung 7 - Erweiterter Workflow
Abbildung 7 - Erweiterter Workflow
Fazit
Die Konzepte, die zur Optimierung von Flow wesentlich sind, stehen teilweise im Gegensatz zu langläufigen Überzeugungen. Deshalb ist es wichtig, die Zusammenhänge zu verstehen, um das volle Potenzial nutzen zu können. Wer sich darauf einlässt, dem verspricht dieses Vorgehen nicht nur bessere Ergebnisse, sondern auch entspannteres Arbeiten. Teams, die offen sind, mit Flow zu experimentieren, können die Konzepte schrittweise umsetzen und so selbst Erfahrungen sammeln, wie sich das auf ihre Arbeitsweise und die Ergebnisse auswirkt. Verschiedene Metriken können genutzt werden, um diese Veränderungen transparent zu machen. Während einige davon bereits hier beschrieben wurden, soll der nächste Teil dieser Artikelserie einen tieferen Einblick geben.
Weiterführende Folgen zur Artikelserie zu Kanban:
Teil 1 - Let there be flow – Die Magie hinter Kanban und Flow (dieser Artikel)
Teil 2 - Flow mit Metriken beherrschen -> Hier weiterlesen
Teil 3 - Flow mit Azure DevOps -> Hier weiterlesen
Scrum und Kanban - Konkurrenten oder Dreamteam?
Scrum und Kanban werden oftmals als Alternativen behandelt. Oder eher als ein Baukasten, aus dem man sich die Elemente auswählt, die momentan gut für die eigene Situation passen und Dinge, die eher stören würden, die kann man weglassen. Während grundsätzlich nichts gegen ein individuell angepasstes Vorgehen spricht, bei dem man sich Praktiken aus verschiedenen Welten bedient, sollte man sich dabei eine wichtige Frage stellen: „Gehen wir damit nur den Weg des geringsten Widerstands?“ Der Sinn hinter der Einführung agiler Methoden ist schließlich, dass eine Veränderung stattfinden soll. Lässt man Regeln, Praktiken oder Elemente nun einfach weg, besteht die Gefahr, dass man damit eben Veränderung vermeidet. Scrum kann sehr gut durch die Flow-Konzepte in Kanban verbessert werden ohne dass dabei Scrum Regeln wie im Scrum Guide vi formuliert, verletzt werden müssten. Ein solches Model ist beispielsweise im Kanban Guide for Scrum Teams beschrieben.
Sie finden das Thema spannend und möchten mehr darüber erfahren? Vielleicht ist das Professional Scrum with Kanban Training für sie interessant?
Oder sie vereinbaren einen Termin zu einem kostenlosen und unverbindlichen Gedankenaustausch.
Termin vereinbaren